ただし、さらに致命的な障害が発生した場合 (たとえば可能なネットワーク パスすべての故障など)、everRun システムはシステム全体の総合状態を判断しようとします。その後、システムはゲスト VM の整合性を保護するために必要なアクションを実行します。
次の例は、致命的な障害発生時のシステムのプロセスを示すものです。
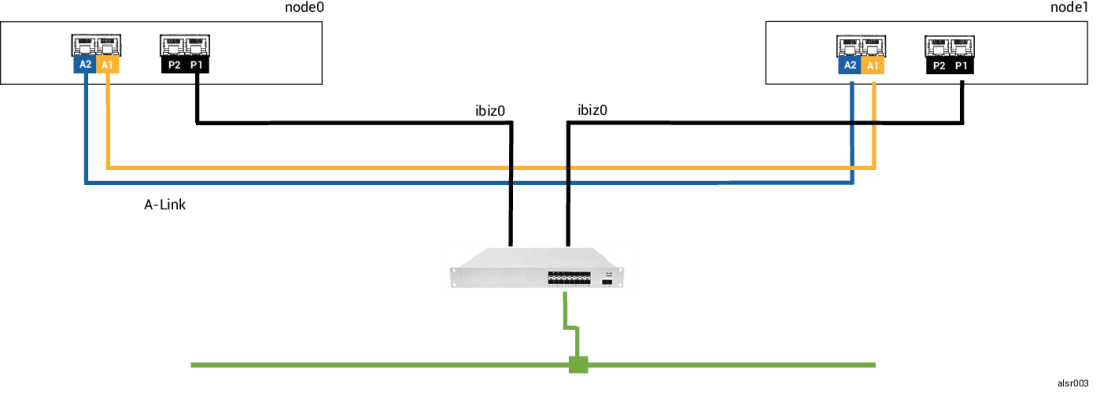
SplitSite の例では、everRun システムに node0 と node1 が含まれますが、クォーラム サーバは含まれません。動作は正常で、現在検知されている障害はありません。2 つのノードは正常な (障害のない) 動作のときと同様に、A-Link 接続を介してその状態と可用性をやり取りします。次の図は正常な接続を示すものです。
フォークリフトを運転する作業員が不注意から壁に衝突し、すべてのネットワーク接続 (ビジネスリンクと A-Link の両方) を切断してしまいました。ただし電源は残っており、システムも実行を継続しています。次の図は障害のある状態を示すものです。
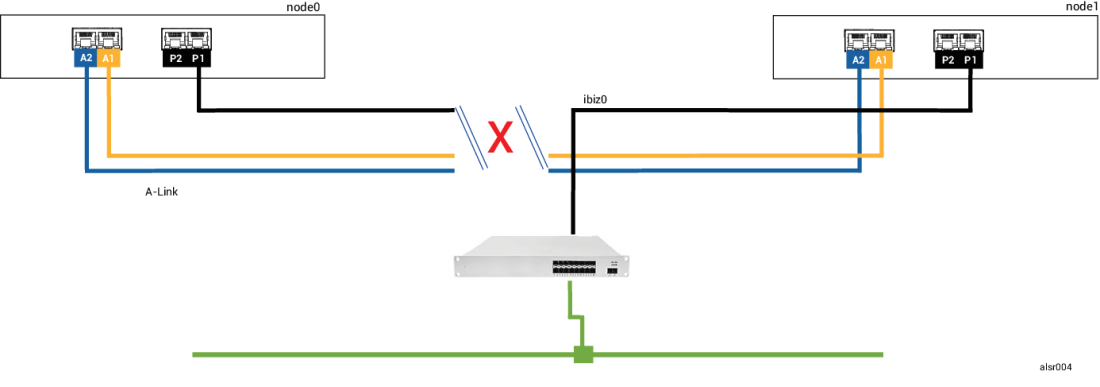
2 つのノードは次のように障害を処理します。
アプリケーション クライアントまたは外部オブザーバの観点からは、ゲスト VM の両方がアクティブであり、同じ返信アドレスでネットワーク メッセージを生成しています。両方のゲスト VM がデータを生成し、それぞれ異なる量の通信エラーを検知します。ゲスト VM の状態は、時間が経つにつれて相違が大きくなります。
しばらくしてネットワーク接続が復元され、壁の修理が済みネットワーク ケーブルの配線もやり直しました。
AX ペアの各 AX は、それぞれのパートナーがオンラインに戻ったことを認識し、障害処理規則のある AX ペアが、アクティブな状態を続ける AX を選択します。この選択は予測が不可能であり、スプリット ブレーン状態の間にどちらのノードのパフォーマンスがより正確であったかを一切考慮に入れません。
(その時点での) スタンバイ ノードから生成されたデータはアクティブ ノードの再同期によって上書きされるため、(その時点での) スタンバイ ノードにあるデータは永久に失われます。
スプリット ブレーン状態の後、システムが再同期を完了するまで数分間かかります。この所要時間はスタンバイ ノードに送信が必要なディスク アクティビティの量によって決まります。異なるアクティブ ノードをもつゲスト VM がいくつか実行されている場合、両方向の同期トラフィックが生じることがあります。
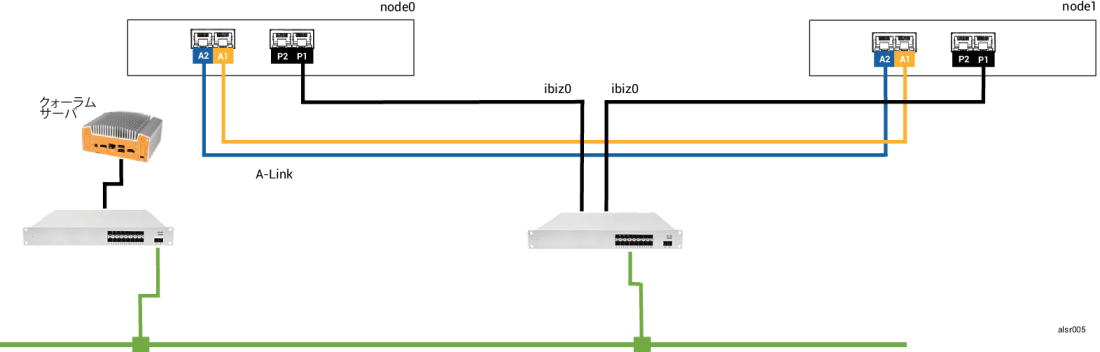
この SplitSite の例では、everRun システムに例 1 のシステムとまったく同じ接続をもつ node0 と node1 が含まれています。これに加えて、例 2 のシステムにはクォーラム サーバが含まれます。次の図はこれらの接続を示すものです。
例の不注意な作業員が再びフォークリフトで壁に衝突し、ネットワーク接続をすべて切断してしまいました。ただし電源は残っており、システムも実行を継続しています。次の図は障害のある状態を示すものです。
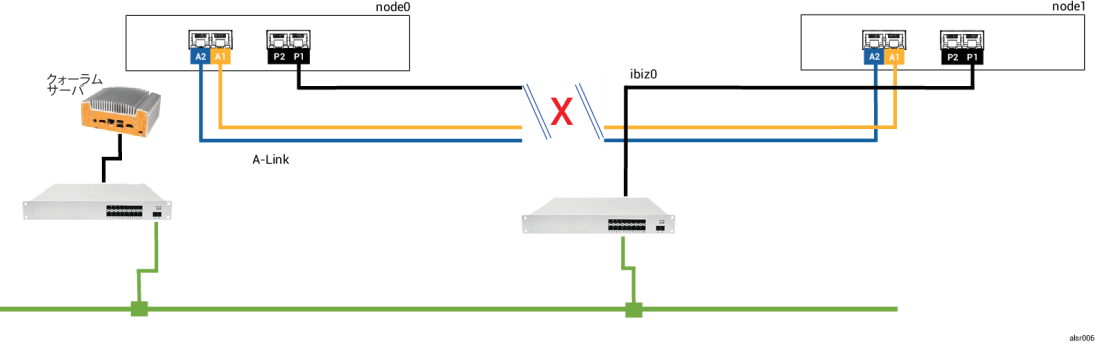
2 つのノードは次のように障害を処理します。
アプリケーション クライアントまたは外部オブザーバの観点からは、node1 のゲスト VM はアクティブなままになり、node0 の VM がシャットダウンしている間もデータを生成します。スプリット ブレーン状態は存在しません。
しばらくしてネットワーク接続が復元され、壁の修理が済みネットワーク ケーブルの配線もやり直しました。
node1 AX でそのパートナーがオンラインに戻ったことが認識されると、node0 AX がスタンバイになります。node0 は以前実行中ではなかったので、node1 から node0 へのデータ同期が開始されます。
スプリット ブレーン状態は発生していないので、データ損失はありません。
システムが再同期を行うには数分間かかります。この所要時間はスタンバイ ノードに送信が必要なディスク アクティビティの量によって決まります。
クォーラム サーバのある
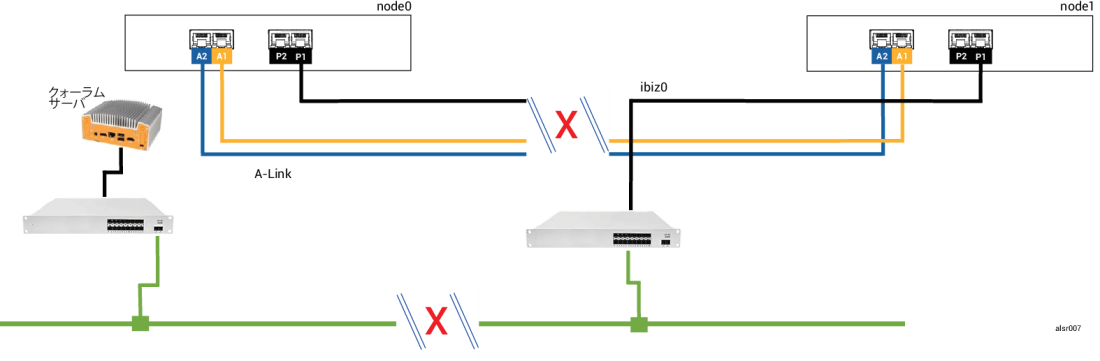
障害処理は例 2 の場合と似ていますが、node1 に重要な違いが 1 つあります。
この場合、ゲスト VM が node0 と node1 の両方でシャットダウンされ、スプリット ブレーンの発生は回避されます。トレードオフは、node0 とクォーラム サーバのどちらかへの接続が復元されるまでゲスト VM が利用不可になる点です。
その場合、運用しない方のノードを特定し、その電源を切ります。次に、運用する方のノードを強制ブートしてら、VM を強制ブートします。VM をシャットダウンしてから起動する方法については、「仮想マシンの運用を管理する」を参照してください。)
場合によっては、致命的な物理的障害がなくてもクォーラム サーバがアクセス不可になる可能性があります。これはたとえば、OS パッチの適用などの定期的なメンテナンスのためにクォーラム コンピュータがリブートされる場合などです。こうした状況では、クォーラム サービスが応答していないことが AX で検知されるため、AX はクォーラム サーバへの接続が復元されるまで同期のトラフィックを中断します。ゲスト VM は、接続が失われた時点でアクティブだったノード上で実行を継続します。ただし、追加の障害が発生する可能性があるため、ゲスト VM はスタンバイ ノードに移行しません。クォーラム サービスが復元された後、クォーラム サーバへの接続が維持されていれば、AX は同期と通常の障害処理を再開します。
停電やシステム シャットダウンの後にシステムを再起動する場合、everRun システムはゲスト VM の起動を行う前に、まずそのパートナーがブートして応答するまで待機します。以前アクティブだった AX がクォーラム サーバにアクセスできる場合には、AX がパートナー ノードのブートを待たずにゲスト VM を直ちに起動します。以前スタンバイだった AX が最初にブートした場合、この AX はパートナー ノードを待機します。
システムがパートナー ノードまたはクォーラム サーバのいずれかから応答を受け取ると、正常な運用が再開されて VM が起動します。その際、その他のケースと同じ障害処理規則が適用されます。
システムがクォーラム サーバからの応答を受け取らない場合や、システムにクォーラム サーバがない場合、ユーザが手作業でゲスト VM を強制的にブートする必要があります。これは AX または障害処理機能によって下されたすべての判断を上書きします。node0 と node1 でそれぞれ異なるユーザが同じゲスト VM をブートすることは避けてください。そうすると、誤ってスプリット ブレーン状態を引き起こす結果となります。